
Design of generative AI-powered pedagogy for virtual reality environments in higher education

Study 1, Needs Analysis, focused on identifying the needs for the pedagogical use of AI and VR solutions. Many digital tools labeled as AIEd are designed to address specific educational or institutional needs10. To investigate the educational needs and to answer RQ1, we (author UHR) collected two datasets of teachers’ ideas for using emerging technologies in their teaching. This Needs Analysis, conducted using qualitative descriptive methods, was planned to inform the next phase, Pedagogical Design.
In Dataset 1, 30 meetings with 31 university teachers from different disciplines were held. Some teachers attended several meetings accompanied by one to three colleagues, while 13 teachers only participated in individual one-on-one meetings with the researcher. The university teachers represented 9 faculties and one research institute (Table 8) at UH, and they had varying years of teaching experience, with nine being professors. 18 female and 13 male educators participated in the research; age ranged from early 30s to 60s, with the majority in their 40s or 50s (exact ages were not requested).
In Dataset 2, the participants were 35 teachers from different levels of the educational system, from K12 to higher education, who volunteered to submit their ideas regarding the use of ChatGPT in education in public groups on social media. These participants were not asked to provide demographic information.
The study followed the guidelines from the Declaration of Helsinki, Finnish National Board on Research Integrity (TENK), and GDPR compliant practices while collecting, analyzing, storing, and publishing the data. After the meetings with teachers for Dataset 1, all the teachers gave informed, signed consent to allow the researcher’s own meeting notes to be used for this research. All the data was anonymized and cannot be linked to an individual respondent. Dataset 2 was gathered in a public exercise, which was clearly known to all the participants, so there was no need to ask for individual consent.
For Dataset 1, during 17 months in 2022–2023, researcher UHR met with university teachers as part of the Serendip development project at UH, focusing on AI and VR experimentation. Meetings, both online and in-person, lasting 1–2 h, were initiated by either the teachers or the researcher. In these meetings, the researcher gathered teachers’ reflections and ideas for the Serendip development project. Notes from each meeting were compiled into a single document (Word, Microsoft 2024), and anonymized data were stored in the university’s digital cloud storage (OneDrive, Microsoft 2024).
Dataset 2 was gathered through a public competition organized by the Technology Industries of Finland, aimed at encouraging educators to explore the potential of using ChatGPT (as a representative of LLMs in general) in various educational levels. This initiative was in response to the common tendency towards banning ChatGPT in education. Educators were tasked to submit their positive ideas on how ChatGPT could be utilized in teaching and learning. The competition was announced in January 2023 across three Finnish Facebook groups: Opettajien vuosityöaika, ICT opetuksessa, and Mytech. Submissions were public written posts in the mentioned Facebook groups, allowing for community engagement where everyone could comment on and enhance each other’s ideas.
The language of the written ideas and the meeting notes was Finnish, so the quotes used in Study 1 have been translated freely into English by the researcher (UHR).
The chosen analysis method was inductive thematic analysis, which identifies themes from data sources such as interviews50,51. This method involves open coding and grouping findings to identify relevant themes52. We followed the six steps outlined by Braun and Clarke53,54 without any prior assumptions, categories, or theories.
The first step was Familiarizing with the data. This included repeated reading of the data, searching for meanings and patterns. Notes were taken and ideas for coding developed while reading. The second step Generating initial codes, included the production of initial codes from the data. Coding was done by writing notes and comments on the text that was under analysis. From Dataset 1, there were altogether 28 initial codes, and from Dataset 2, there were 22 initial codes (see Table 9).
In the third step, Searching for themes, the coded data was tabularized in a spreadsheet. The findings were then inserted into an online whiteboard (Miro, RealtimeBoard Inc. 2024), and a visual mind map was created with the initial codes for both datasets separately. Similar kinds of codes were grouped into preliminary thematic groups. Three themes were found from the Dataset 1: challenges, general learning ideas, and discipline-specific ideas. From Dataset 2, four themes were identified: ChatGPT fostering AI literacy, ChatGPT acting as a character, ChatGPT improving learning, and ChatGPT as a teacher’s help.
The fourth step was Reviewing themes. In this phase, the coded data was reviewed again, and themes were analyzed. Then the dataset was checked to see if it reflects the identified themes accurately. Two themes from Dataset 1 were combined into one in this phase, leaving two themes for Dataset 1: challenges in current teaching and opportunities of emerging technologies in teaching. The four themes in Dataset 2 remained as above.
During the fifth step, Defining and naming themes, the final refinements could be made after the thematic map of the data was satisfactory. In this phase, the key was to identify the essence of what each theme is about. The themes were considered as themselves but also in relation to the others. In this phase, the categories were also named for each theme, for both datasets separately. At the final step, the report was written as result of this study. The interesting content, which demonstrated the essence of the points, was chosen from the data and provided as citations. To produce a conclusion and to answer RQ1, the findings from both datasets were combined into one table (Table 3).
The study on Pedagogical Design started by choosing the applicable reference framework. For sustainability education, the sustainability competency framework was found suitable as it provided the structure for sustainability competencies, related learning objectives, and instructional methods32,33,34. Subsequently, the author, N.M.A.M.H., identified the feasible learning objectives and their corresponding instructional methods suitable for IVR. Consequently, to answer RQ2, the following three design steps were formulated regarding the design of GAI-powered characters for pedagogical purpose in IVR:
-
1.
Selecting the applicable reference framework.
-
2.
Identifying the learning objectives and instructional methods that could be feasible in IVR.
-
3.
Designing the GAI characters.
After the initial design was formulated, it was discussed with chosen domain experts to confirm the design ideas before doing extensive prompt engineering for the GAI characters. After the iterative design and prompt engineering, the chosen domain experts tested the design to be able to address RQ3. The outcomes of this design process, covering the three design steps utilized in this study, are presented in the “Results” section.
With the goal of deploying the 3D GAI characters in the IVR learning environment, these characters were initially developed as text-based characters using CurreChat (UH’s user interface for GPT 4). Reflecting the UNESCO guidelines, author N.M.A.M.H. followed the practices of prompt engineering: continuous refinement, iteration, and experimentation of the outcome3. For Tero, prompt engineering entailed over 25 testing rounds, covering more than 400 questions. Madida underwent 24 testing rounds with over 225 questions. The prompt for testing Madida required a relatively smaller number of questions, because the exercise intended with Madida includes a limited number of questions36 that are structured to help the student in preparing the presentation of the backcasting exercise.
Study 2 aimed to evaluate the human-GAI interaction quality and the utility of the GAI characters as pedagogical tools. It also sought to gather insights from domain experts to further develop these characters and to inform product development and research, addressing RQ3. A deductive qualitative content analysis55 was employed, based on categories identified in Study 1, to achieve these objectives. Initially, the domain experts interacted with the two GAI characters, which were developed in text format at this stage with UH’s GPT interface (CurreChat). Subsequently, semi-structured interviews56 were conducted with domain experts who have the expertise and knowledge relevant to the two GAI characters. Five semi-structured interviews were conducted to test the two GAI characters (three for Tero and two for Madida) to elicit in-depth information from interviewees (i.e., domain experts) aligned with the study’s focus55.
The interviews focused on domain experts’ reflections and insights about the GAI characters. Structured guiding questions were formulated—five for Tero and four for Madida—to elicit detailed responses while avoiding ‘yes-or-no’ questions.
The guiding interview questions for Tero were as follows (in this order):
-
What is your impression?
-
To what extent is the information provided by Tero relevant and accurate?
-
To what extent does Tero reflect a real forest owner?
-
What are your opinions about Tero’s forest management plan?
-
What are your suggestions for further development of the conversation with Tero?
For Madida, the guiding interview questions were as follows (in this order):
-
What is your impression?
-
To what extent is the information provided by Madida relevant and accurate?
-
To what extent does the exercise with Madida reflect a real backcasting presentation preparation exercise?
-
What are your suggestions for further development of the conversation with Madida?
For Study 2, testing the two GAI characters involved conducting 5 interviews with 8 domain experts from UH (Table 10). Testing for Tero involved three semi-structured interviews: the first with two forest sciences domain experts, the second with three sustainability education domain experts, and the third with one forest sciences domain expert. For Madida, two testing sessions were held, each involving one backcasting domain expert.
The domain experts were contacted and invited to participate in multiple live testing sessions held between 2022 and 2024. Participation was voluntary, and consent forms were obtained prior to testing. Prompts engineered for the GAI characters were added to UH’s CurreChat yet remained concealed from the testers. After individually testing the text-based characters for 20–30 min, the domain experts participated in semi-structured interviews. These interviews were recorded. The final interview data consisted of two video recordings, one audio recording, one speech-to-text file, and interview notes. All data collected during the interviews were securely stored in UH’s own cloud storage (OneDrive, Microsoft 2024).
The study followed the guidelines from the Declaration of Helsinki, Finnish National Board on Research Integrity (TENK), and GDPR compliant practices. Participants were instructed not to disclose any sensitive information during discussions with the GAI. Furthermore, all participants signed a consent form to participate in the research, and their identities were anonymized prior to analysis.
All the tested features are provided by the UH Serendip developer team according to the UH safety and privacy regulations. The developed text-based AI prototypes are using UH’s own GDPR-safe GAI interface CurreChat, which utilizes an LLM developed by OpenAI. It is in the Microsoft Azure cloud service of the UH in the EU region. The information input into the service is not used to further train the LLM. Additionally, no user identification information is passed on to the language model. No discussion data is saved in the system.
To address RQ3, the interview data underwent qualitative content analysis55. The analysis aimed to evaluate how well the two pedagogical GAI characters developed for this study met the educators’ needs identified in Study 1. For this purpose, the selected method for Study 2 was content analysis using the deductive approach. Deductive content analysis is utilized when the analysis is built on the basis of previous information55. Therefore, the deductive approach was found suitable for analyzing the experts’ insights during testing, based on the needs already identified in Study 1, thereby addressing RQ3. The deductive approach to content analysis in this study followed the three main phases identified by Elo & Kyngäs: preparation, organizing, and reporting55.
The first phase of the content analysis was preparation. In this phase, complete familiarity with the data was achieved, the unit of analysis was determined, and a focus on the manifest content was established. Familiarity was gained by Author N.M.A.M.H. as she led and transcribed all interviews. Each session’s notes were written immediately afterward, and all recordings (videos and audio) were manually transcribed and reviewed to ensure accuracy. This involved multiple reviews of the interviews to reach a high level of data comprehension. Then, a separate document (Word, Microsoft 2024) was created, containing verbatim transcriptions of all the recorded data (videos and audio), the speech-to-text file, and the interview notes from all five interview sessions. Thus, all interview data, including questions posed by the interviewer and responses from the experts, were compiled into this document (Word, Microsoft 2024) for thorough analysis. The unit of analysis was identified as the sentence(s) within each response, which were chosen because they conveyed specific ideas or insights. Some ideas were expressed in single sentences, while others spanned multiple sentences. The analysis was strictly focused on the manifest content, deliberately excluding any latent elements such as laughter55. This approach was chosen to more accurately assess the effectiveness of the GAI characters (as the designed solution) in meeting the educators’ needs identified in Study 1.
The second phase was organizing. This phase entails deciding on the categorization matrix for the deductive content analysis, developing the coding frame, coding the data, and analyzing the data based on the matrix. Since the co-first authors had already discussed and reached consensus on the grouping of needs into categories—along with their meanings, similarities, and differences—in the conclusion of Study 1, this agreed-upon categorization matrix (see Table 3) was used as the basis for the deductive content analysis in Study 2. A second document (Word, Microsoft 2024) was created for the development of the coding frame based on the needs analysis identified in Study 1 (Table 3). Eleven out of the 12 identified needs were given a two-digit code each, while one need was branched into two sub-categories, each given a three-digit code. In each code, the first digit represents the main category, and the second digit represents the generic category. For instance, the identified need (AI acting as a character being a learning companion) was given (Code 1.2); the first digit “1” represents the main category of “AI acting as a character,” and the second digit “2” represents its generic category of “being a learning companion.” The remaining need out of the 12 is the need for “Emerging technology to help the teacher with personalized teaching,” where the generic category of “personalized teaching” was further branched into two sub-categories: “differentiating learning paths” and “providing linguistic possibilities for lesson planning.” Therefore, each sub-category of “personalized learning” was given a three-digit code: (Code 3.3.1): “Personalized teaching: Differentiating learning paths” and (Code 3.3.2): “Personalized teaching: Linguistic possibilities for lesson planning.” The final coding frame is illustrated in Fig. 3.
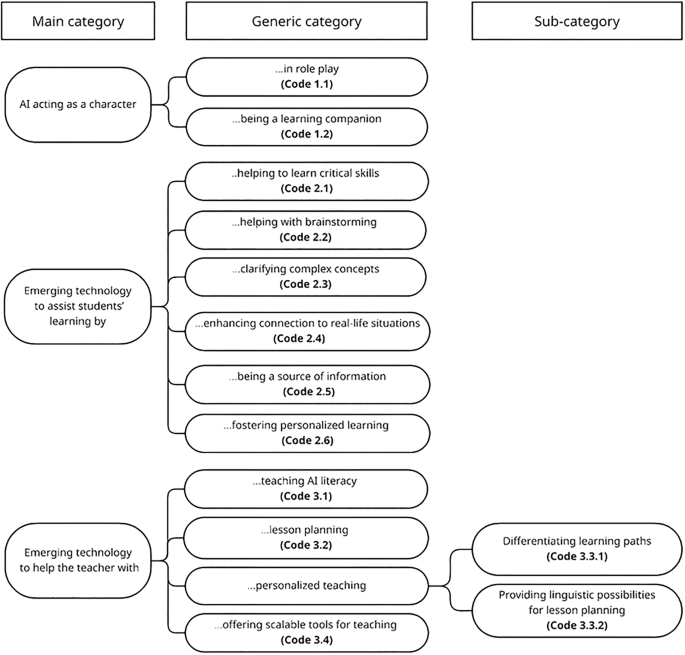
Coding frame used for analyzing data in Study 2.
To address RQ3, which investigates how well the designed GAI-powered characters met the teachers’ identified needs, it was necessary to select data aspects that aligned with the categorization matrix of the teachers’ identified needs (Table 3). The data in Study 2 were coded according to this categorization matrix. This involved comparing sentences to each identified need and then marking the sentences with their corresponding codes using the comment function in the document (Word, Microsoft 2024). Throughout the coding process, constant reference was made to the meanings of each category to ensure the sentences accurately matched each category. After coding the entire dataset, a third document (Word, Microsoft 2024) was created featuring a table with three columns: the first column contains the experts’ needs along with its corresponding code; the second column provides an explanation of the need; and the third column includes the corresponding sentences from the testing sessions, copied and pasted as quotations.
The third phase was reporting. Relevant quotations that illustrated these needs (i.e., codes) were categorized and listed in Table 11. Codes not supported by data findings were removed from the matrix (2.4, 3.1, 3.3.1, and 3.3.2). Additional details of the reporting were provided in the “Results” section.
link





